BluRayHiDef
Banned
RDNA2 is manufactured on the "7nm" manufacturing process of Taiwan Semiconductor Manufacturing Company (TSMC), whereas Ampere is manufactured on the "8nm" manufacturing process of Samsung. Despite the actual sizes of these manufacturing processes not being consistent with their marketing names (hence I've put them in quotation marks), TSMC's "7nm" process is indeed smaller than Samsung's "8nm" process, which is what's important to consider.
Hence, because RDNA2 is manufactured on the smaller process, it packs more transistors per square millimeter. For example, the following calculations show the difference in transistor density between RDNA2's largest consumer chip, Navi 21, and Ampere's largest consumer chip, GA102.
Navi 21: 536 square millimeters and 26.8 billion transistors -> 26.8 billion/536mm^2 = 50,000,000 transistors per square millimeter
GA102: 628.4 square millimeters and 28.3 billion transistors -> 28.3 billion/628.4mm^2 = 45,035,009.5 transistors per square millimeter
50,000,000 / 45,035,009.5 = 1.110247351 -> 1 - 1.110247351 = 0.110247351 -> 0.110247351 x 100 = 11.0247351% -> 11%
This additional 11% of transistors per square millimeter is why RDNA2 performs as well as it does in rasterization relative to Ampere even though Ampere has more transistors overall; the entirety of Ampere's 28.3 billion transistors cannot be used exclusively for rasterization since many of them comprise RT Cores and Tensor Cores that exclusively perform ray tracing and artificially intelligent upscaling, respectively. While the exact number of transistors that comprise RT Cores and Tensor Cores is not known, we can be sure that they amount to more than the difference in the overall number of transistors in RDNA2 and Ampere (28.3 billion - 26.8 billion = 1.5 billion) based on diagrams that illustrate the relative sizes of CUDA Cores, RT Cores, and Tensor Cores.
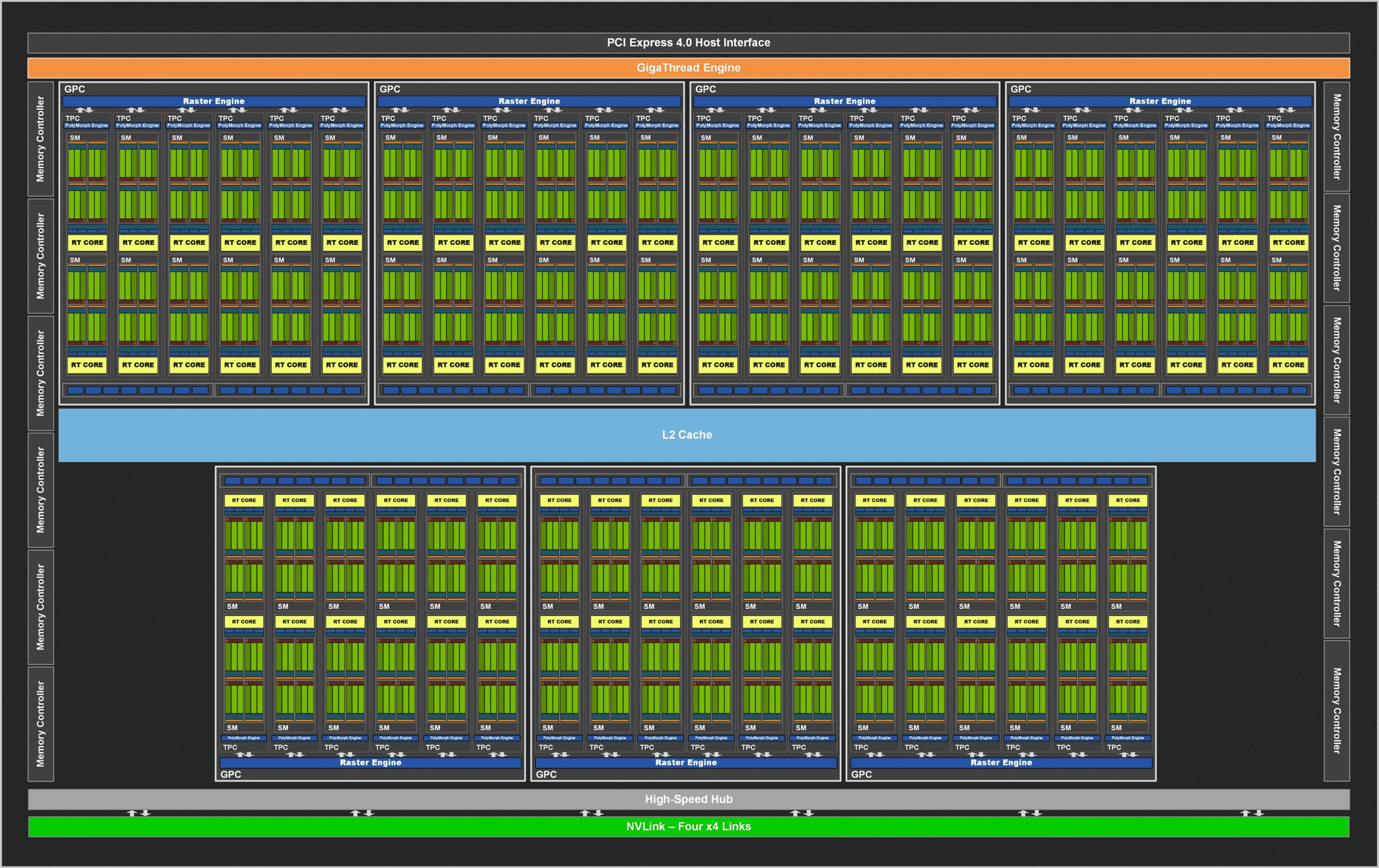
Hence, Ampere performs roughly as well as RDNA2 in rasterization with less transistors.
This indicates that RDNA2 isn't as efficiently designed as Ampere or - at the very least - isn't as efficiently put to use by AMD's drivers as Ampere is put to use by Nvidia's drivers. This assertion is based on rationale: an additional 11% of transistors should always result in better performance in rasterization (when other features are not enabled), but as AMD themselves showed at their announcement event, RDNA2 is faster than Ampere in rasterization only some of the time and is barely so whenever it is.
Hence, despite having more transistors per square millimeter and despite being able to use all of them for rasterization (whereas Ampere can use only some of its transistors for rasterization), RDNA2 is only as fast or slightly faster than Ampere in rasterization. Hence, RDNA2 isn't as impressive as it seems.
It can be argued that RDNA2 is indeed more efficient because it's performing as well as it is in rasterization relative to Ampere despite using less power; Navi 21 uses 300 watts at most at stock settings but GA102 uses 350 watts at most at stock settings. However, it must be considered that Navi 21 is - once again - manufactured on a smaller manufacturing process, that 300 watts is only 16.7% less than 300 watts, and that Navi 21 uses more transistors for rasterization (which naturally require less power since they don't have to function as fast as a lower number of transistors).
Hence, if Ampere were to be refreshed on TSMC's "7nm" manufacturing processes, it would be outright faster than RDNA2 in rasterization.
Hence, because RDNA2 is manufactured on the smaller process, it packs more transistors per square millimeter. For example, the following calculations show the difference in transistor density between RDNA2's largest consumer chip, Navi 21, and Ampere's largest consumer chip, GA102.
Navi 21: 536 square millimeters and 26.8 billion transistors -> 26.8 billion/536mm^2 = 50,000,000 transistors per square millimeter
GA102: 628.4 square millimeters and 28.3 billion transistors -> 28.3 billion/628.4mm^2 = 45,035,009.5 transistors per square millimeter
50,000,000 / 45,035,009.5 = 1.110247351 -> 1 - 1.110247351 = 0.110247351 -> 0.110247351 x 100 = 11.0247351% -> 11%
This additional 11% of transistors per square millimeter is why RDNA2 performs as well as it does in rasterization relative to Ampere even though Ampere has more transistors overall; the entirety of Ampere's 28.3 billion transistors cannot be used exclusively for rasterization since many of them comprise RT Cores and Tensor Cores that exclusively perform ray tracing and artificially intelligent upscaling, respectively. While the exact number of transistors that comprise RT Cores and Tensor Cores is not known, we can be sure that they amount to more than the difference in the overall number of transistors in RDNA2 and Ampere (28.3 billion - 26.8 billion = 1.5 billion) based on diagrams that illustrate the relative sizes of CUDA Cores, RT Cores, and Tensor Cores.
Hence, Ampere performs roughly as well as RDNA2 in rasterization with less transistors.
This indicates that RDNA2 isn't as efficiently designed as Ampere or - at the very least - isn't as efficiently put to use by AMD's drivers as Ampere is put to use by Nvidia's drivers. This assertion is based on rationale: an additional 11% of transistors should always result in better performance in rasterization (when other features are not enabled), but as AMD themselves showed at their announcement event, RDNA2 is faster than Ampere in rasterization only some of the time and is barely so whenever it is.
Hence, despite having more transistors per square millimeter and despite being able to use all of them for rasterization (whereas Ampere can use only some of its transistors for rasterization), RDNA2 is only as fast or slightly faster than Ampere in rasterization. Hence, RDNA2 isn't as impressive as it seems.
It can be argued that RDNA2 is indeed more efficient because it's performing as well as it is in rasterization relative to Ampere despite using less power; Navi 21 uses 300 watts at most at stock settings but GA102 uses 350 watts at most at stock settings. However, it must be considered that Navi 21 is - once again - manufactured on a smaller manufacturing process, that 300 watts is only 16.7% less than 300 watts, and that Navi 21 uses more transistors for rasterization (which naturally require less power since they don't have to function as fast as a lower number of transistors).
Hence, if Ampere were to be refreshed on TSMC's "7nm" manufacturing processes, it would be outright faster than RDNA2 in rasterization.




