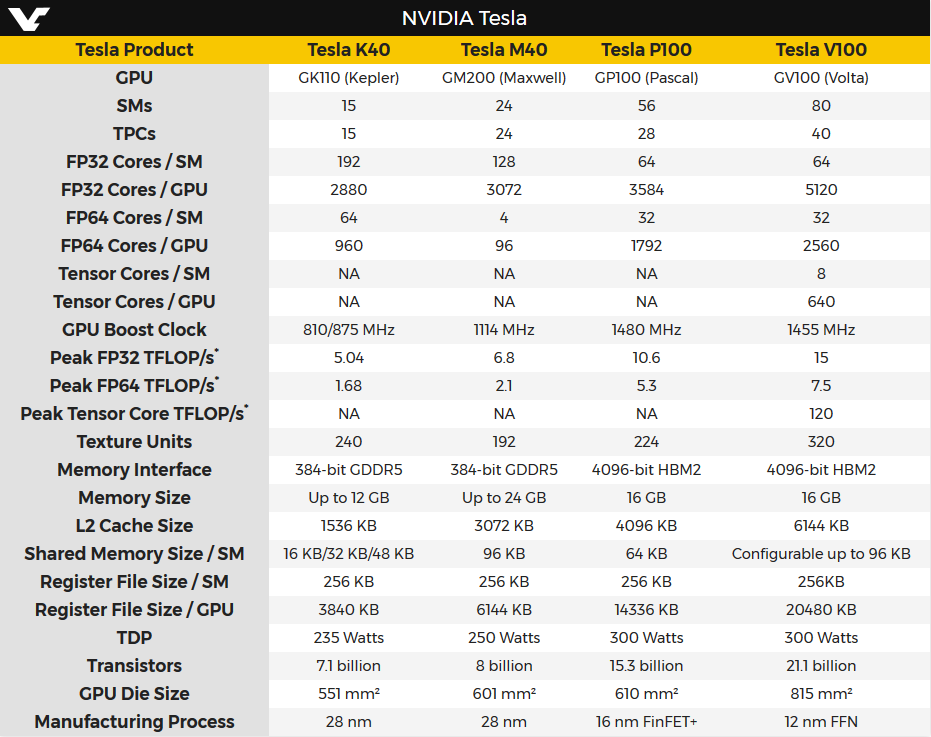
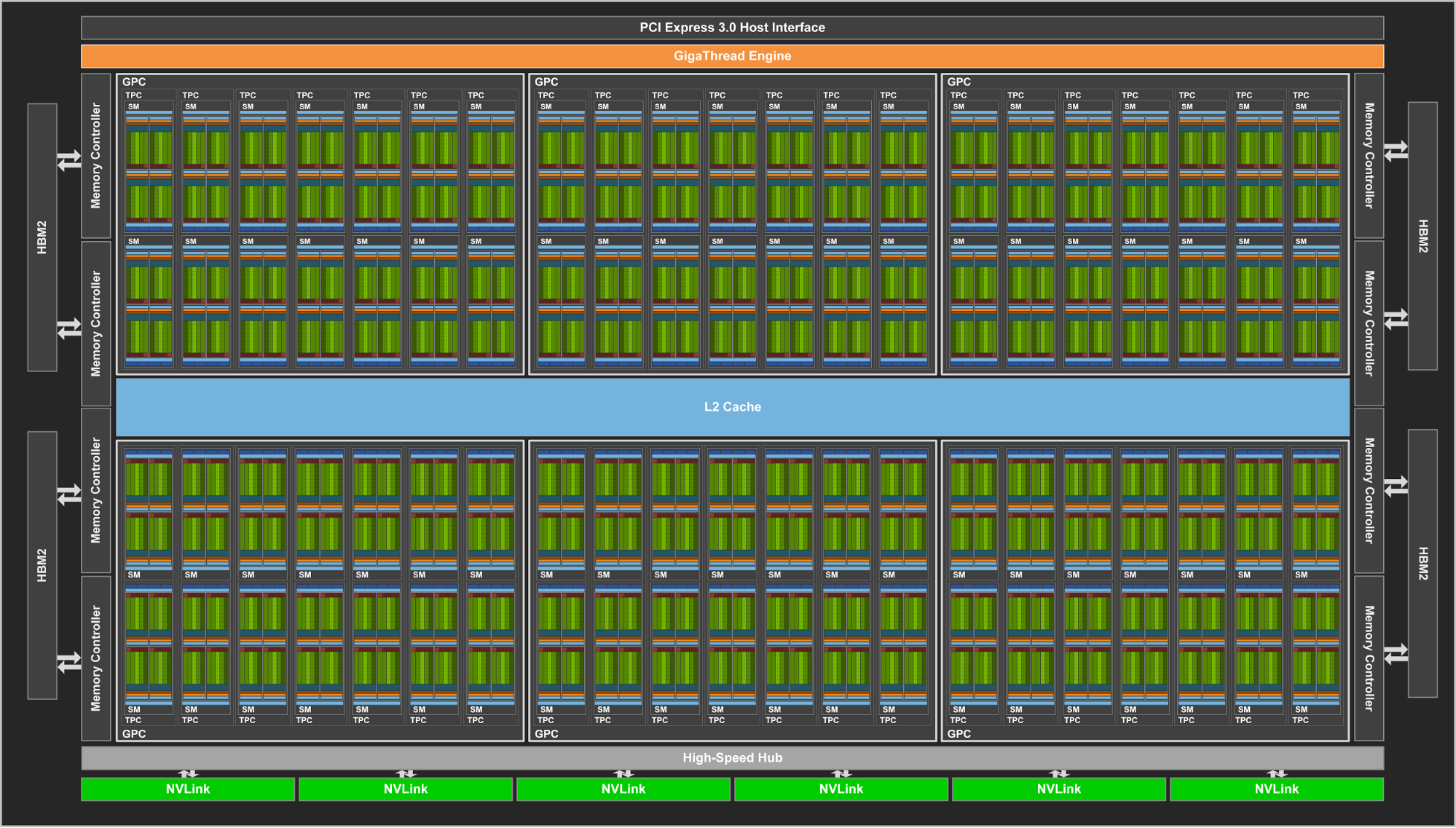
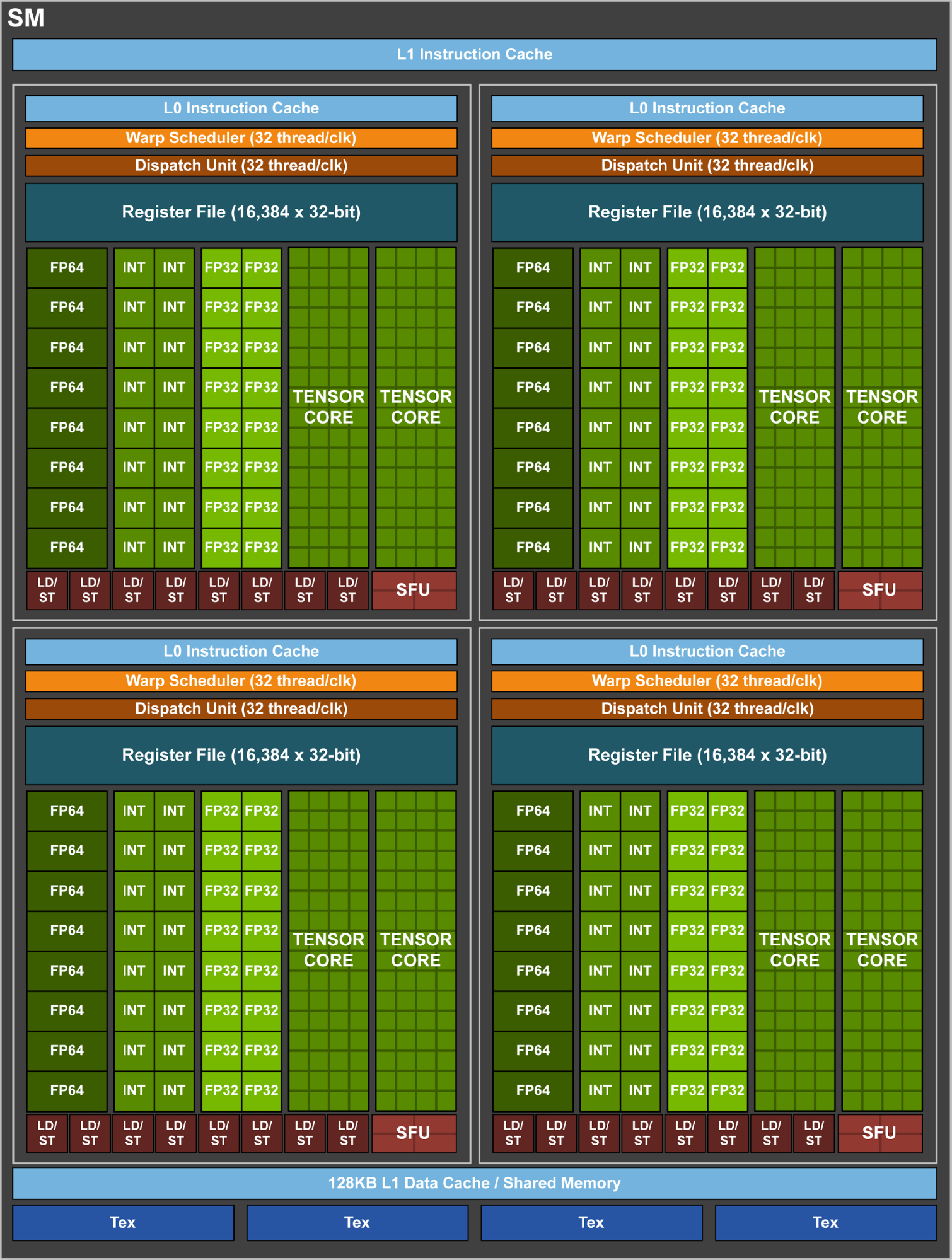
Similar to Pascal GP100, the GV100 SM incorporates 64 FP32 cores and 32 FP64 cores per SM. However, the GV100 SM uses a new partitioning method to improve SM utilization and overall performance. Recall the GP100 SM is partitioned into two processing blocks, each with 32 FP32 Cores, 16 FP64 Cores, an instruction buffer, one warp scheduler, two dispatch units, and a 128 KB Register File. The GV100 SM is partitioned into four processing blocks, each with 16 FP32 Cores, 8 FP64 Cores, 16 INT32 Cores, two of the new mixed-precision Tensor Cores for deep learning matrix arithmetic, a new L0 instruction cache, one warp scheduler, one dispatch unit, and a 64 KB Register File. Note that the new L0 instruction cache is now used in each partition to provide higher efficiency than the instruction buffers used in prior NVIDIA GPUs.