Again.
VRS = Variable Rate Shading.
Variable Rate Shading in done at Geometry Engine time before you draw.
Sample Feedback (it is a software logic not hardware feature) has two uses only.
Streaming.
Texture Space Shading.
So I don't think we are talking about texture streaming (that is a non issue with faster SSDs) here so it is basically used for Texture Space Shading.
Anyway both Streaming Texture and Texture Space Shading can be done without Sample Feedback logic.
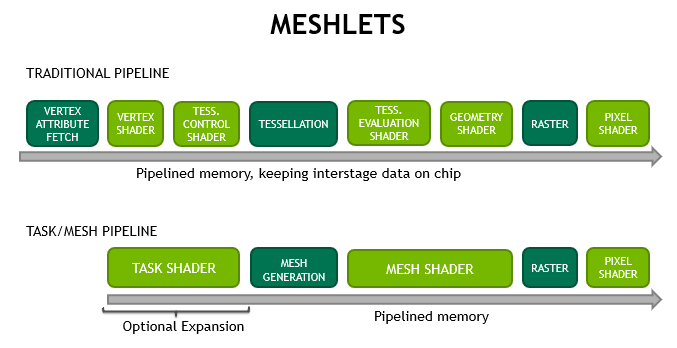
Mesh Shaders are Primitive Shaders on AMD side.
It is done by the Geometry Engine.
All these features are related/done by Geometry Engine on AMD hardware.
Geometry Engine is not a single hardware unit... there is a lot of small units that do these works before the draw... for example there are 4 Primitives Shaders units inside the Geometry Engine.