DonMigs85
Member
Dang, thought it was 80. So PS5 can actually beat it in raw fillrate but lags in memory bandwidth and shader powerXSX has 64 ROPs confirmed.
Dang, thought it was 80. So PS5 can actually beat it in raw fillrate but lags in memory bandwidth and shader powerXSX has 64 ROPs confirmed.
XSX has 64 ROPs confirmed.

These ACTUAL multi-plat game comparisons can't come soon enough. I am so fucking tired of speculation.
No need to evolve then. Just don’t devolve into the lower life console warrior.
It has the same amount of ROPs (64).I think the Series X has more ROPs and TMUs to compensate for its clock deficit right? Heck even the One X had half the ROPs of PS4 Pro but the memory bandwidth and shader count more than made up for it
Bolded
1) I did?
2) You've already undone your argument. The Gflops we talk about in console terms are a purely theoretical paper calculation of shader ALUs * 2 ops per core per clock * clock speed. By talking about optimization, you've already acknowledged this is far from all there is to it.
It also only looks at shader theoretical performance alone. The Xbox certainly has more. But that's not all there is on a GPU, as Cerny alluded to, several developers, DF, NX, and others have winked at. A 23% clock speed advantage also means everything else is clocked higher on the GPU, the command processors, the buffers, the caches, the coprocessors, there may be other advantages to the GPU outside of the peak shader theoretical performance console warriors like to boil things down to. That's without considering the geometry engine, API differences, etc.
TMUs 208Going to send a correction to the Techpowerup GPU database guy, seems to be leading some astray
AMD Xbox Series X GPU Specs
AMD Scarlett, 1825 MHz, 3328 Cores, 208 TMUs, 64 ROPs, 10240 MB GDDR6, 1750 MHz, 320 bitwww.techpowerup.com
Going to send a correction to the Techpowerup GPU database guy, seems to be leading some astray
AMD Xbox Series X GPU Specs
AMD Scarlett, 1825 MHz, 3328 Cores, 208 TMUs, 64 ROPs, 10240 MB GDDR6, 1750 MHz, 320 bit
Going to send a correction to the Techpowerup GPU database guy, seems to be leading some astray
AMD Xbox Series X GPU Specs
AMD Scarlett, 1825 MHz, 3328 Cores, 208 TMUs, 64 ROPs, 10240 MB GDDR6, 1750 MHz, 320 bit
The correct contextual performance metric for a single teraflop is 4 trillion calculations a second.
Attempting the redefine/confuse the teraflop metric by citing CU count's are worthless even when it take's less CU's to produce more Teraflops. Teraflop's the metric that matters - CU count's will always effectively grow or shrink with architecture improvements - as needed - but should not be considered the relevant performance metric in relation to Teraflop Performance.
A Teraflop is not a theoretical metric. A Teraflop is a concrete measurement of 4 trillion calculations. Period. To imply a teraflop in theory might perform 4 trillion calculation's a second is to imply it really isn't capable of 4 trillion calculations in most cases.
The correct contextual performance metric for a single teraflop is 4 trillion calculations a second.
Attempting the redefine/confuse the teraflop metric by citing CU count's are worthless even when it take's less CU's to produce more Teraflops. Teraflop's the metric that matters - CU count's will always effectively grow or shrink with architecture improvements - as needed - but should not be considered the relevant performance metric in relation to Teraflop Performance.
A Teraflop is not a theoretical metric. A Teraflop is a concrete measurement of 4 trillion calculations. Period. To imply a teraflop in theory might perform 4 trillion calculation's a second is to imply it really isn't capable of 4 trillion calculations in most cases.
Also, a Teraflop does much more than shader performance. A single Teraflop is also indicative of pure polygon count. As you wrongly cited, "It also only looks at shader theoretical performance alone" And polygon count's are not shader performance - shader's are a derivative texturing/overlay methods that allow the artist's to do more with less and a Teraflop in fact effects all object's on screen not just shader performance.
Please see here where I predicted both Consoles performance in Teraflop's (and calculated/added CPU teraflop performance for both systems - which is exactly 1 teraflop with each CPU) exactly 2 year's ahead of their reveal using my expertise in computer science and cgi creation to learn more.
Can you please post the information confirming this, I've only heard it rumored but not confirmed.XSX has 64 ROPs confirmed.
No, there will be always a shadow with a slightly lesser resolution on one machine than the other. Thousands of posts and hours of videos will be poured.Multiplat games will look almost identical next gen.
Makes me wonder if this will make DF redundant.
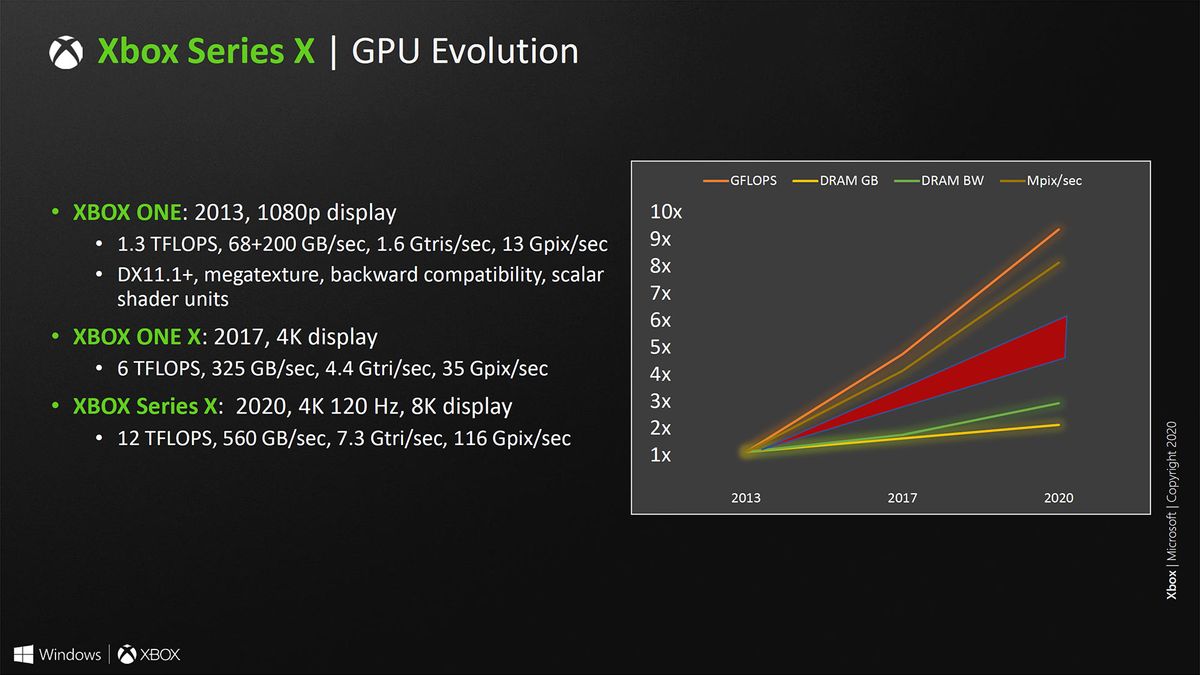
Information (hot chips slide) about the ROPs is at 15 min. "116 Gpix/sec", he should correct it. I dont know about the TMU's sadly.
I have to agree with you. In the beginning the rumours and speculations are kinda interesting... but after a while it gets so damn tiring. I can't wait to see the real deal.These ACTUAL multi-plat game comparisons can't come soon enough. I am so fucking tired of speculation.
There are some strange statements in the last few posts.
Every additional CU to a GPU adds less output than the previously added CU. This is a mathematical fact unless a task can be parallelised to 100% (which no task can).
Secondly, under heavy load the bottle-neck for a GPU is most often the unified cache (L2 in AMDs language) which results in CUs either idling or doing redundant work (i.e. performs a task that is either no longer required or is done by another CU). This is a real problem and if you look around at solutions where people try to increase cache efficiency on GPUs you can see crazy numbers such as +50% in actual output in terms of computational performance.
Since we lack data on the PS5's cache system it is hard to make a comparison. All we know is that Sony has spent some serious work in trying to increase cache efficiency. We will see if they have succeeded.
However, as seen in the +50% number above good cache management can yield much better results if done right than just adding CUs. Please note that I am not claiming that the PS5 is getting +50% output from the CUs - it is just an example to make clear that proper cache management can yield results that are much more impressive than a few % in increased actual performance.
Lysandros I didn't watch the Redtechgaming video(I'm working right now), however he references Hot Chips and the Hot Chips Series X presentation ...transcript.... does NOT mention ROPS....so does RedTechGAming have unreleased, insider(or claiming insider) information or is he just guessing? It does NOT seem to be CONFIRMATION, but just a guess.

Just google Xbox series X GPU Evolution and you'll see that slide yourself. No need to mention the 'ROPs', it says 116 Gpix/sec right in the microsoft presentation slide. The only way of having this number knowing the clock frequency is via 64 ROPs. It's known quantity since almost two months. Anything else?..
MS own Hot Chips presentation confirmed it in August.
Thank you! I couldn't manage to add that image for some reason.Hot Chips presentation confirmed it.

Man, I can almost taste the facetiousness in this post...
Anyway, it's like I said earlier about the PS5 caches being "faster"; that's something that begins to factor in if the graphical tasks in question need a certain duration of cycles to where it actually becomes a factor. Otherwise, on a cycle-for-cycle basis, the larger GPU with the larger physical amount of cache is going to be able to crunch more data in parallel than the smaller GPU with a smaller physical array of cache.
I don't know what was being discussed before my reply, but everything I'm bringing up fits neatly into that discussion. It's contingent to it, it's pertinent. You don't get to determine something that fits relatively close in with what you were discussing prior (does not physical cache allocation on the L0$ level affect CU efficiency? I surely would think it does) just because it brings up a point you either didn't consider or, in light of being indicated, don't like.
Why would it not be possible to increase the L1$ size? These systems are at least on 7nm DUV Enhanced; even a few slight architectural changes here and there would allow for more budget to cache sizes. I'm not saying it's 100% a lock they did increase the L1$ size, just that it's premature to assume they did not, when they've already increased the L2$ amount.
Otherwise yes, it's true if the L1$ sizes are the same for both then Series X feeds more at a 20% reduced speed. But you won't be needing to access the L1$ frequently in the first place if you have more physical L0$ allowing for a higher amount of unique data to be retained in the absolute fastest cache pool available. And that's where, on same architectures, the larger GPU has a very clear advantage in; always have and always will (unless we're talking about GPUs of two different architectures where the smaller one has a much larger L1$, but that's not what we're dealing with here regards RDNA2. Only discrete GPUs I can think of doing this are some upcoming Intel Xe ones that are very L0$-happy).
It'd be really nice if we stopped confusing cache speed with cache bandwidth. IMO the former should pertain to overall data throughput measured in overall time (cycle) duration. The latter should pertain to single-cycle throughput, which is dependent on actual cache sizes. Assuming L1$ is the same, their bandwidth is the same and the speed advantage for a given graphical task getting crunched on the caches only starts showing a perceptible difference in favor for that with the faster clocks if a certain threshold of data processing for that task in the caches is done. We can apply this to the L0$ as well.
No, because if PC GPU benchmarks are anything to go by many, MANY reserve a chunk of the VRAM as just-in-case cache, even if the game isn't actually occupying the cache in that moment of time.
So you'd think smarter utilization of the VRAM by cutting down on the use of chunks of it as a cache would make better use of it...thankfully MS have developed things into XvA like SFS to enable that type of smarter utilization of a smaller VRAM budget. Sony has a great solution too; it's different to MS, but both are valid and make a few tradeoffs to hit their marks. At least regarding MS's, I don't think those tradeoffs are what you're highlighting here, going by extensive research into this.
You do realize the RAM still needs to hold the OS, CPU-bound tasks and audio data, correct? Realistically we're looking at 14 GB for everything outside of the OS reserve for PS5 (NX Gamer's brought up the whole idea of caching the data to the SSD before; not that it's a realistic option IMHO outside of some tertiary OS utilities seeing as how the vast bulk of critical OS tasks expect the speed and byte-level addressable granularity of volatile memory to work with), and if we're talking games with similar CPU and audio budgets on both platforms, at most you have 1 extra GB for the GPU on PS5 vs. Series X, but you sacrifice half a gig of RAM for CPU and audio-bound data.
Yes it does have a faster SSD but there's still a lot of aspects of the I/O data pathway that are apparently CPU-bound once the data is actually in RAM.
Glad we agree on this part.
Just because MS happens to have more TF performance doesn't mean they didn't aim for a balanced design target, either. This is a common misconception and comes from a binary mode of thinking, where everything's either a hard either/or. Console design is much more complicated than that.

For all the people claiming they were called shills for because of Xbox no it was because one guy claimed halo was ok and wasn't that bad at all it was just "lighting"
I wouldn't call that a shill just a fan not seeing what 90% of people say. Hence after the fact, the game was delayed because even they knew it was not up to par as a next-gen title. I believe it was the first time that I can recall people called them out on something.
Again just a bad review on what he saw
But I thought in the hotchips presentation for the XsX there was someone mentioning that it is either TMUs or RT calcs, but not both at the same time, am I remembering that correctly?It has the same amount of ROPs (64).
TMUs are tied to the CU so it indeed has more.
But I thought in the hotchips presentation for the XsX there was someone mentioning that it is either TMUs or RT calcs, but not both at the same time, am I remembering that correctly?
It is a RDNA 2 thing... the Interceptions are part of the TMUs so they share the same silicon.... if you use for one task you can't use the same for another at the same time.But I thought in the hotchips presentation for the XsX there was someone mentioning that it is either TMUs or RT calcs, but not both at the same time, am I remembering that correctly?
Your talking as if the XSX is slow but wide, and 4 shader arrays its not that wide is it. Also the path L1 to L0 will be longer on the XSX on silicon.
The L1 and L2 sizes are very important and how they are arranged their speed and efficiency, as effective bandwidth = bandwidfth / Factor of cache misses
You will note that the pC RDNA2 parts leaked so far have 10 CU in each shader array, and for the 80 CU part it has 8 shader arrays of 10 CU.
So XSX is certainly the odd arrangement, I suspect they wanted 4 shader arrays because 4 server instances.
At hotchips MS said they could not reveal the L1 cache details or any process details when asked.
Lets see how it works eh ?
Ok whatever, Microsoft has already explained that its not taking advantage of any IPC gains, or any of the newer features of the XSX so if you want to spread FUD go right ahead.We disagree, thats fine, ps4 pro had nearly everything in boost mode Sony were just covering the odd one, I cant think of any of top of my head.
XSX was not cut down in CU, and it was running DX code, emulating or abstract api is a fine line of definition as its the MS way of operation.
Emulating is just wrong, its X86 and DX12 so no, just no.
Saying CGN game code is different to RDNA game code is why that dev mocked, and so do I.
By theoretical, I mean it's a calculated measure of the peak output of the system. You can't seriously say there's never any difference between a paper calculation of all of ALUs * clock speed * 2 ops per ALU per cycle, vs a graphics chips output in real world performance. Are there never differences in cache contention? Hit rates? Bandwidth? Schedulers? Keeping the ALU's filled with relevant non redundant work? THAT is the difference between a measurement of the peak flops and real end performance, otherwise why do you think performance between generations and architectures can't be compared purely by looking at peak flops?
Vega killed Nvidia, because more flops? Right? Right? No, because...No.
No one is saying one teraflop is a different number than what it is. What everyone DOES understand is a paper figure is one thing, applying the performance to real world graphics is another, and the difference between the two would be the utilization rate and various other factors.
it's too early for this kind of revisionism and the other video about halo you're not taking into account for it to be somewhat true will not disappear too.For all the people claiming they were called shills for because of Xbox no it was because one guy claimed halo was ok and wasn't that bad at all it was just "lighting"
I wouldn't call that a shill just a fan not seeing what 90% of people say. Hence after the fact, the game was delayed because even they knew it was not up to par as a next-gen title. I believe it was the first time that I can recall people called them out on something.
Again just a bad review on what he saw
MS noted this and made the hot swap SSD which is liked a lot.
The info after AMD share it on the Infinity Cache and the PS5 "scrubbers" will likely not be a happy moment for some either.
I personally, in fact do compare performance between generation's/architectures by looking specifically at Teraflop performance - and then consider what these improved architectures mean for software performance IN RELATION TO TERAFLOP performance. Higher faster rated memory does often not effect teraflop performance directly - but as a computer scientist and overclocker for about 20 years now - faster memory does allow you to overclock the cpu and gain more Teraflop performance. Teraflops are real world, real "end" performance metrics. And this is what ALL SANE GAME DEVELOPERS AND COMPUTER SCIENTISTS look at when determining how much to simulate/and what type of game they can create aside from the benefit's of near instantaneous ssd loadtimes.
This is a reductionists viewpoint of viewing load scheduling for task deployment among the CUs. If the scale of the work is not predicated on a certain amount of unique data to be distributed among those blocks of CUs, then the advantage favors a system that can run more parts of the instruction in parallel than the one that runs them faster, because the latter predicates itself on previous parts of the data pipeline for the instruction to be calculated beforehand.
Computer science 101.
Actually when you think about it, the concern itself is invalid in the first place. Try applying this to the CPU space 15 years ago: by that logic, we should've simply kept cranking up the clocks. But engineers realized a reality when it comes to pushing clocks too high. At some point, parallelism wins out as a design metric. We are starting to see the benefits of that from AMD themselves, going with larger discrete GPUs, never mind Nvidia or Intel who are in similar pursuit (especially the latter). So I'd say market realities would indicate that these companies, including AMD, have addressed the vast majority of concerns regarding frontend saturation of their GPU resources. After all, you kind of need to have done that in order to further pursue things such as chiplets, which AMD are rumored to be doing for RDNA3 (no word from Nvidia on that front yet; both trail behind Intel in the chiplet area for GPUs however).
Okay...so, where does this suddenly mean only PS5 sees this "good cache management"? Again, it's binary thinking: A chose to go with X, so A cannot have also chosen Y. That type of stuff. No company is making their decisions that way, it's foolish to pretend that they are.
Both systems have smart cache management. We already know Series's GPU can snoop the CPU caches, and the inverse is true as well (but software-only in that case). Technically speaking, if the GPU can snoop the CPU caches, that is an analogous approach in cache management comparable to cache scrubbers. In many ways they're attempting to resolve the same issues when it comes to stale data in the GPU caches to sync with correct data in those caches while attempting to cut down on flushing the entire caches or taking a hit going back to main memory for the data to copy back into the caches.
So again, there's really very little "either/or" hard massive compromises on either system. They're taking smart approaches in every part of the pipeline borrowing bits from anything relevant. The sooner this is accepted as a common-sense conclusion I think a lot of the FUD WRT either would die off drastically. But until then, we'll just keep debating where we feel it's merited.
The correct contextual performance metric for a single teraflop is 4 trillion calculations a second.
Attempting the redefine/confuse the teraflop metric by citing CU count's are worthless even when it take's less CU's to produce more Teraflops. Teraflop's the metric that matters - CU count's will always effectively grow or shrink with architecture improvements - as needed - but should not be considered the relevant performance metric in relation to Teraflop Performance.
A Teraflop is not a theoretical metric. A Teraflop is a concrete measurement of 4 trillion calculations. Period. To imply a teraflop in theory might perform 4 trillion calculation's a second is to imply it really isn't capable of 4 trillion calculations in most cases.
Also, a Teraflop does much more than shader performance. A single Teraflop is also indicative of pure polygon count. As you wrongly cited, "It also only looks at shader theoretical performance alone" And polygon count's are not shader performance - shader's are a derivative texturing/overlay methods that allow the artist's to do more with less and a Teraflop in fact effects all object's on screen not just shader performance.
Please see here where I predicted both Consoles performance in Teraflop's (and calculated/added CPU teraflop performance for both systems - which is exactly 1 teraflop with each CPU) exactly 2 year's ahead of their reveal using my expertise in computer science and cgi creation to learn more.
Ok whatever, Microsoft has already explained that its not taking advantage of any IPC gains, or any of the newer features of the XSX so if you want to spread FUD go right ahead.
You sure write a lot while saying little. If me calling ALUs shaders is your gochya, have it, I was around when they unified pipelines and it's a force of habit.
Let me focus on this as the meat of what you said. Real world, end performance. Yes. Those measurements are absolutely real. But that's not what console wanking numbers are, no one has measured the output of these things outside of closed doors yet. As in, what we're talking about is only the peak use of all hardware on paper.
And as I cited originally - this is because through more efficient software optimization - the concrete metric of 1 Teraflop ='s 4 trillion calculations per second - on these new architecture's
And it's not all software. When a pipeline stalls for work, or a cache miss, that increases the gap between what an architecture can do on paper, and what it really does. Why, in your words, did AMD architectures underperform Nvidia per flop, at least until the near future, if then? Why Nvidia's focus on command processors keeping the ALU utilization rate up, to historically the detriment of peak flops? Software is never going to magically use every flop available and jump past every architectural bottleneck, that's just magical thinking.
You should get reimbursed, here is an extract from some research paper on the subject:Computer science 101.
Peak performance, by whatever metric you choose be it Tflops, triangles/sec, etc. Is always theoretical because it assumes full resource utilization at the time of measurement.
Its a rough measure at best because real-world workloads are never the same operation x million times, its a huge variety of things each with their own contingencies and propensity for bottle-necking/stalling. Hence you can have massive potential Teraflop counts but see less actual performance in practice because other parts of the pipeline are lowering occupancy.
There are real, practical benefits to trying to methodically eliminate inefficiencies across the board, versus simply ramping up raw capacity. The perception problem is that on PC's particularly, the overall system architecture is typically mostly homogenous especially for benchmarking purposes, allowing for variances to be tied down to a narrow set of metrics. Hence the fixation on rough stats like Tflop count as the "true" measure of performance, when all its actually demonstrating is that when all else-is-equal this parameter has the most pronounced impact.
P.S. Thanks for the laugh with that giant Reddit thing. Most outlandish fan-fic I've read I've read in awhile. MS business model is real simple: Sell subscriptions to as wide an audience as possible. The end.
No, they said its not using rDNA2 features, such as VRS and mesh shading which has to be programmed for specfically. Or SFS for that matter.
Anything that is done automatically will be used when called on by the apis.
Which things have I sdaid that is made up ?
Just because it might go against your thoughts does not mean it is fUD, thats called giving up the debate.

while Series X runs old games with full clocks, every compute unit and the full 12 teraflop of compute, it does so in compatibility mode - you aren't getting the considerable architectural performance boosts offered by the RDNA 2 architecture.
"Compatibility mode", "emulates", and " not coded for RDNA 2", it literally can't get any clearer then that.There may be the some consternation that Series X back-compat isn't a cure-all to all performance issues on all games, but again, this is the GPU running in compatibility mode, where it emulates the behaviour of the last generation Xbox - you aren't seeing the architectural improvements to performance from RDNA 2, which Microsoft says is 25 per cent to the better, teraflop to teraflop. And obviously, these games are not coded for RDNA 2 or Series X, meaning that access to the actual next-gen features like variable rate shading or mesh shaders simply does not exist.
You should get reimbursed, here is an extract from some research paper on the subject:
We illustrate that many kernels scale in intuitive ways, such as those that scale directly with added computational capabilities or memory bandwidth. We also find a number of kernels that scale in non-obvious ways, such as losing performance when more processing units are added or plateauing as frequency and bandwidth are increased. In addition, we show that a number of current benchmark suites do not scale to modern GPU sizes, implying that either new benchmarks or new inputs are warranted.
You do realize that you do not even contradict me with your statements
Of course there is value in adding cores. I simply pointed out that each additional core offers less of an performance boost than the previously added core. The performance discount increases with how hard a specific task is to parallelize. Fortunately, graphical pipeline tasks are relatively easy to parallelize. Let's us make an arbitrary example. Let's assume that a graphical task has 2% of workflow that cannot be parallelized (probably in the vicinity of the truth). Let us assume that each CU adds 1 TFLOPs in theoretical performance (ofc silly - just for simplicity)
First CU adds 1 TFLOP. Second CU adds 0.98 TFLOP.
Already here you can conclude that going wide is good. You would need to increase frequency by a whooping 98% to compete with adding one more CU - going wide is your choice.
Third CU would add 0.96 TFLOP....tenth CU would add 0.82 TFLOP.
At 10 CUs you would list your GPU as having a theoretical max of 10 TFLOPs in performance. However, that number can never be achieved. Even under perfect circumstances you will only get 9.15 TFLOPs due to that 2% of your GPU workflow cannot be parallelized even though your technology specifications list 10 TFLOPs. Most people do not realize this hard truth. The more CUs, the wider the gap is between that theoretical TFLOP number and your actual TFLOP performance.
Every manufacturer is sitting with these trade-offs. Adding CUs vs increasing frequency. Increasing frequency requires also faster memory and a better cooling solution - both adds cost. It is a complex equation.
Your assumption that cache management is well handled is very much contradicted by research papers in this field - there is a lot to get from better task distribution and cache management. Real GPU utilization is not even close to 100% during rendering as it is today regardless of what your hardware monitor is stating.
We know some things. We know that PS5 has hardware pieces to manage caches that the XSX does not have.
Then we have indications (we need more data) that seemingly the PS5 has more L2 cache per CU than the XSX and unless the XSX has increased the L1 cache size compared to the standard RDNA2 design, the PS5 also have more L1 cache per CU compared with the XSX. L0 caches are most likely identical.
So there is data to indicate that the PS5 has a better cache management system than the XSX: Larger cache per CU at the L1 and L2 levels, hardware features to manage those caches and increased cache memory frequency
. As you rightfully point out the XSX has a system to use the CPU caches as an 'L3' cache - however that is not the same as the cache scrubbers. Cache scrubbers keep track of what data that can be purged at the cache level to increase cache turnaround times. Using the CPU cache is a cache overflow system. Two different things.
In reality, putting all this together, the PS5 will perform closer to the theoretical max TFLOP number that the XSX.
How much closer? Only tests with applications that are optimized on both will tell the story. And as I have stated before, given the new GE in the PS5 I believe the first multi-plats will perform better on the XSX simply because of an underutilized GE on the PS5 - I might be wrong of course but that is what I assume.

Wow, a whole one research paper! How many people are in this field, again? How long ago was this paper you written dated? Was it in reference to specific commercial GPUs (highly unlikely), or generic theoretical GPU models (more likely)?
Might want to consider these things before posting them carte blanche. Like I said, GPU saturation has always traditionally been a thing sought for resolving over the years, but today's cards from today's vendors have pushed closer to solving this particular issue than any generation of the past.
Eventually, GPUs will perfectly match the parallelized function of modern-day multi-core CPUs; right now they are on the cusp of it, some more than others. You would hope AMD are one of those at the edges of being there; after all that would benefit both pieces of plastic at the end of the day.