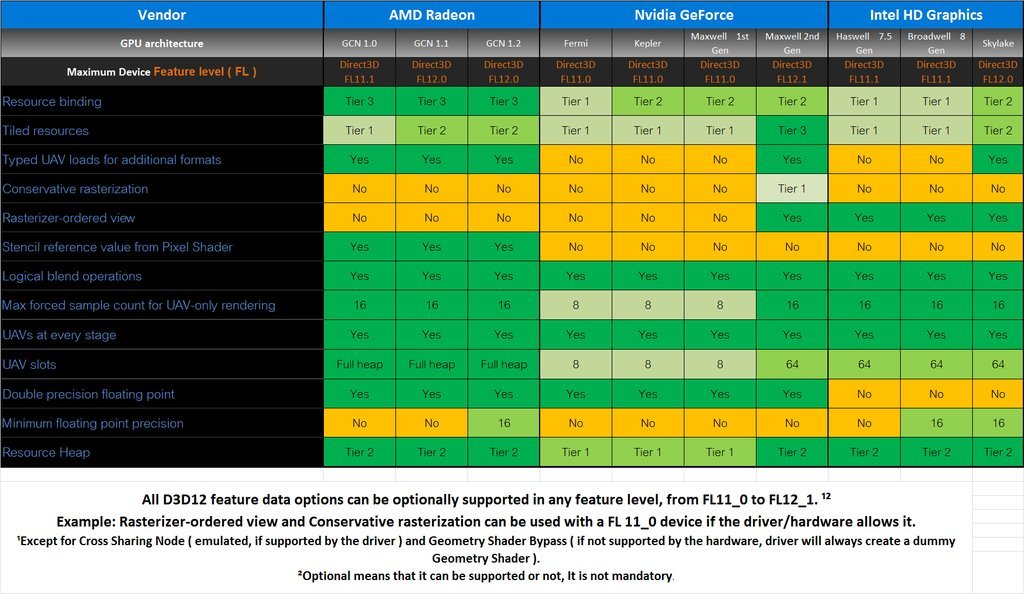
There's nothing generous in saying that the different behaviour may be because of pre-emption granularity difference.
I'm saying that referring to a non-granular system as merely having a "granularity difference" is generous and misleading. You're implying that NV's approach is somewhat granular, but it really isn't.
How do you know that it's "broken"? Are all i5s "broken" compared to i7s since they don't have HT enabled? What about if we look at gaming workloads specifically?
I refer to it as "broken" because NV refer to it as "fully compliant." Yes, it doesn't crash in response to the command, but the operations intended to improve performance instead degrade it. So I assume it's actually
intended to deliver the claimed functionality, and generously refer to it as broken, yes. But you may be right too; maybe it was never intended to work correctly, and they were just misleading us when they said it would.
A lot of people around here are claiming that and AMD seems to be claiming that as well.
Then I imagine you won't have any trouble providing us with some links.
If there are such resources which is totally dependent on the GPU's architecture.
Completely untrue. There are always unused resources, because not every processor is needed in every phase of the rendering pipeline. Try to keep up.
"Noticeable" can mean anything. They aren't giving an exact figure which makes me doubt that it's anything to brag about.
So you claim they admitted to not getting a lot of performance out of the feature, despite his actual statement being that he got a noticeable improvement with only a modest amount of effort. When I call you out on completely misrepresenting what he said, your defense is, "No,
he's the liar!!" ><
It is a useful technique on some architectures, it is not on the others and there is no direct indication of not being able to coupe just fine without it in DX12.
It's a useful technique on any architecture that implements it correctly.
Right, and the results of Kepler cards which are showing total time as even less than compute+graphics are what exactly? You also seems to miss the part where Maxwell cards are several times faster than GCN ones even doing compute+graphics serially.
This benchmark isn't designed to test actual performance; the GCN cards are dispatching jobs half-filled. This benchmark merely tests for the presence of fine-grained compute. The AMD cards pass that test, while the NV cards fail. We can't compare fine-grained performance because the current NV cards aren't capable of doing it at all.
There is no clear understanding of what's going on in this benchmark right now so don't try to oversimplificate what we're looking at.
Did that clear things up for you?
I wouldnt interpret beyond3d's benchmark yet, it needs a lot of tweaking.
Why? My GTX 970 outperforms Fury X in compute by factor of 5 and by factor of 3 when its using async.
Again, this isn't a performance test. It merely test for the presence of fine-grained compute.
Lololol, butthurts everywhere.
Your Pants != Everywhere
I enjoy techie stuff and try to learn how things works
Then you should mock less and listen more.
don't care so much about people feelings about brands tbh.
Yes, clearly.

There is a reason for Horse Armour being that funny in this forum
I didn't think he was that funny. I thought the poor guy was as confused as you are. I was gonna type a long post to try to explain this stuff to him.
I understood very little of the technical stuff. I just have one question: If even without async nVidia cards perform better, why should I care? I want to upgrade my rig and I am completely and utterly confused by all this.
The short version is, if you need a new card today, you're probably better off getting a decent AMD card and as always, newer is better. If you don't need a card today, wait and see if Pascal supports fine-grained compute, and make your decision at that point.
Also I would suggest using the Cerny's Async Fine Grain Compute in this thread, without fine grain there is no performance benefit to go async.
Not entirely true, since merely being asynchronous can free up the CPU to perform other tasks. That said, yes, fine-grained is where the "free compute" comes from; without it, you're forced to halt rendering to run compute jobs.
AMD taking advantage of certain DX12 feature for their own benefit doesn't make that stuff part of DX12.
Dude, you're being fucking ridiculous. You refer to it as a "DX12 feature" yourself. That means it's "part of DX12." You can't even keep your goalposts in the same place for an entire sentence, FFS. ><
Ashes only uses a modest amount according to oxide themselves. I'd say you can expect people like dice, 4a games, and whoever makes graphically advanced games to use a lot more.
Yup.
Modest is certainly one way of putting it. That one post by oxide mentioned 30% (I believe) of their rendering is done through Async or something.
Well, modest is a relative term, and if it's the post I'm thinking of, he also said they could actually move the entire thing to 100% compute, and not do any conventional rendering at all. As I recall, that was actually Kutaragi's original plan for the PS3; pure compute with a second Cell instead of the RSX.
I'm pretty sure we will just get Async ON/OFF in options. Putting post-processing for example with two branches async/non-async probably is quite easy to do, especially when they are already writing it on consoles, so i think many games will use it like that, as a bonus. I bet that most compute tasks are designed first normally and then rewritten to async, so non-async path is always available.
No one will focus whole their compute budget on it though and its not like compute is majority of rendering budget. It is probably up to 30-40% and probably only up to 50% of it are 'asyncable', so generally only like up to 20% gains at most.
Still a nice boost, but nothing really groundbreaking, decreasing precision of some effect or designing better algorithm can yield similar boost on high end settings.
You still don't seem to get it. Yes, there are plenty of tricks you can employ to achieve similar performance gains, but you forget/ignore those same tricks are still available to the fine-grained systems.
So it's a positive for certain architectures, and a neutral for the rest, not necessarily a negative.
Well, more negative than neutral, I'd say, because the context switching can actually penalize them. They actually need to segregate the job types as much as possible to avoid context switching.